3. Análisis exploratorio y visualización¶
Este ejemplo muestra las principales funcionalidades del módulo Exploración, de la librería. Este módulo permite obtener distintas visualizaciones de un texto o conjunto de textos, tales como nubes de palabras, gráficos de barras con los términos más frecuentes y redes de coocurrencias. Estas funciones son útiles para explorar uno o varios textos, y tener mejor idea de qué contienen y sobre qué hablan.
3.1. Importar paquetes necesarios y adecuar texto de prueba¶
Nota
Para este ejemplo, se va a trabajar con el texto de la novela «Don Quijote de la Mancha», escrita por Miguel de Cervantes Saavedra. El texto completo de esta novela se encuentra en la carpeta entrada de la sección de ejemplos del Repositorio de GitHub de ConTexto, y fue descargado desde la página del Proyecto Gutenberg, que tiene a su disposición miles de libros de forma gratuita.
>>> from contexto.lectura import leer_texto
>>> from contexto.limpieza import limpieza_texto, lista_stopwords, remover_stopwords
>>> from contexto.exploracion import grafica_barchart_frecuencias
>>> from contexto.exploracion import matriz_coocurrencias, graficar_coocurrencias
>>> from contexto.exploracion import obtener_ngramas, nube_palabras, par_nubes
>>> # Cargar y limpiar texto de prueba
>>> ruta_cuento = 'entrada/cervantes_don_quijote.txt'
La función lectura.leer_texto() del módulo lectura es utilizada para extraer el texto del archivo que contiene la novela. Luego, se realiza una limpieza estándar del texto, para que esté mejor adecuado para su exploración. Para esto, se utilizan las funciones limpieza.limpieza_texto() y limpieza.lista_stopwords(), del módulo limpieza.
Finalmente, en el texto aparece en varias ocasiones la expresión «project gutenberg», el nombre del proyecto que pone a disposición la novela. Como esta información no está directamente relacionada al texto que nos interesa, se va a remover utilizando la función limpieza.remover_stopwords().
>>> texto_prueba = leer_texto(ruta_cuento)
>>> texto = limpieza_texto(texto_prueba, quitar_numeros=False, n_min=3, lista_palabras=lista_stopwords())
>>> texto = remover_stopwords(texto, lista_expresiones=['project gutenberg'])
3.2. Obtener n-gramas y graficarlos¶
La función exploracion.obtener_ngramas() permite encontrar n-gramas, o conjuntos de n palabras seguidas donde n es un número entero mayor a cero. Por ejemplo, si n=1 o n=2, la función obtendrá las palabras o los bigramas del texto, respectivamente.
Con esta información se puede obtener la frecuencia de cada n-grama, y así conocer cuales son los más mencionados en el texto. Esto puede ser graficado de varias maneras, como por ejemplo mediante nubes de palabras, en las cuales el tamaño de un término es proporcional a su frecuencia de aparición.
>>> # Obtener listas de palabras y bigramas más frecuentes
>>> unigramas = obtener_ngramas(texto, 1)
>>> bigramas = obtener_ngramas(texto, 2)
>>> bigramas[98:105]
['ingenioso hidalgo',
'hidalgo mancha',
'mancha compuesto',
'compuesto miguel',
'miguel cervantes',
'cervantes saavedra',
'saavedra tasaron']
>>> ## Graficar y guardar nubes de palabras y bigramas
>>> # El parámetro "dim_figura" permite definir el tamaño de la gráfica
>>> nube_palabras(texto, n_grama=1, ubicacion_archivo='salida/nube_uni.jpg', semilla=130, dim_figura=(5,5))

>>> # Si se pone "graficar=False", la gráfica no se mostrará.
>>> nube_palabras(texto, n_grama=2, ubicacion_archivo='salida/nube_bi.jpg', hor=0.9, graficar=False)
>>> # Si se utiliza el parámetro "ubicacion_archivo", la imagen generada se guardará en la ubicación especificada
>>> par_nubes(texto, n1=1, n2=2, ubicacion_archivo='salida/nube_uni_bi.jpg')

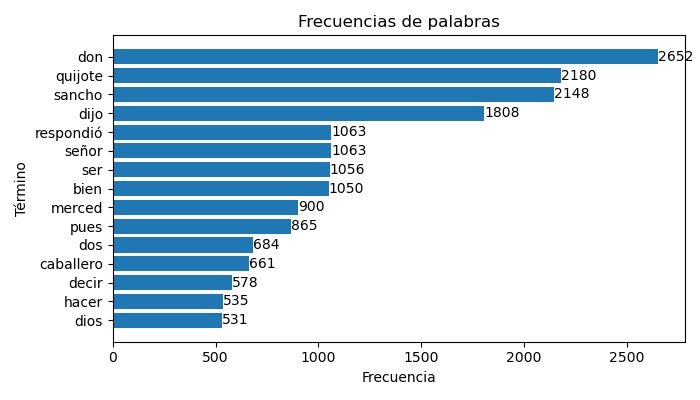
Los n-gramas más frecuentes también se pueden visualizar mediante gráficas más estándar como, por ejemplo, gráficos de barras que muestren los términos más frecuentes. La función exploracion.grafica_barchart_frecuencias() permite obtener estas gráficas.
>>> # Gráficas de barras con las frecuencias
>>> grafica_barchart_frecuencias(texto, ubicacion_archivo='salida/barras_palabras.jpg',
>>> titulo='Frecuencias de palabras', dim_figura=(7,4))
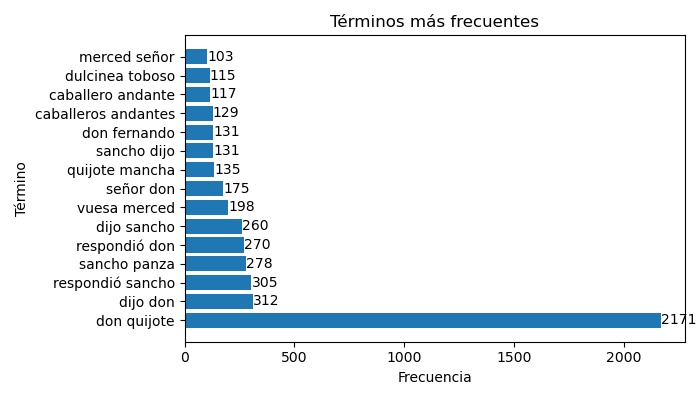
>>> # Si se cambia el parámetro "ascendente" a False, los términos más frecuentes saldrán en la parte de abajo
>>> grafica_barchart_frecuencias(texto, ubicacion_archivo='salida/barras_bigramas.jpg',
>>> n_grama=2, ascendente=False, dim_figura=(7,4))
3.3. Calcular coocurrencias y graficarlas¶
En lingüistica, la coocurrencia es la aparición o utilización conjunta de dos unidades léxicas (por ejemplo, palabras o n-gramas) en una unidad superior, como una oración o un documento. La función exploracion.matriz_coocurrencias() permite calcular las coocurrencias de términos en un mismo documento o en una ventana de +/- n palabras.
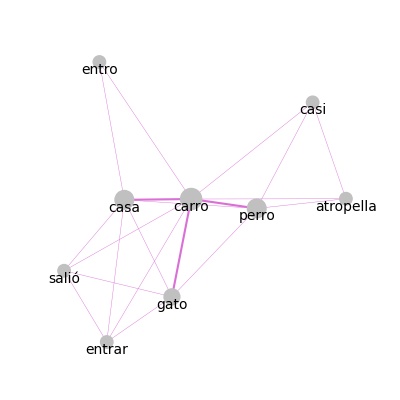
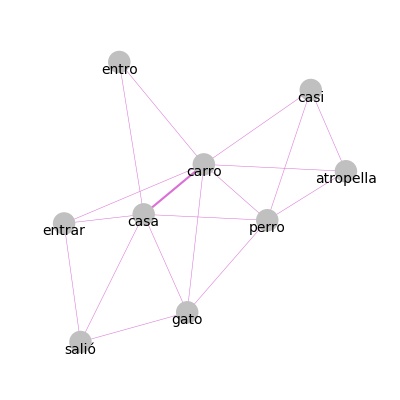
A patir de estas matrices de coocurrencias es posible graficar redes o grafos de coocurrencia, en las cuales el tamaño de cada punto es proporcional a la frecuencia de aparición de ese término y el grosor de las lineas entre puntos es proporcional a la cantidad de veces que dos términos aparecen juntos en un documento o una ventana de palabras.
>>> ## Obtener matrices de coocurrencias
>>> mat_doc = matriz_coocurrencias(texto, max_num=60)
>>> # Solo se cuenta la coocurrencia si las palabras están a 5 o menos palabras entre sí
>>> mat_ven = matriz_coocurrencias(texto, max_num=60, modo='ventana', ventana=5)
>>> ## Graficar co-ocurrencias de palabras en el texto
>>> graficar_coocurrencias(mat_doc, ubicacion_archivo='salida/grafo_doc_full.jpg', dim_figura=(10,8))
>>> # El parámetro "prop_fuera" se utiliza para quitar líneas de menos coocurrencias del grafo,
>>> # con el propósito de simplificar un poco la gráfica
>>> graficar_coocurrencias(mat_doc, prop_fuera=80, ubicacion_archivo='salida/grafo_doc_top20.jpg', graficar=False)
>>> graficar_coocurrencias(mat_ven, ubicacion_archivo='salida/grafo_ven_full.jpg', dim_figura=(10,8))
>>> graficar_coocurrencias(mat_ven, prop_fuera=80, ubicacion_archivo='salida/grafo_ven_top20.jpg', graficar=False)
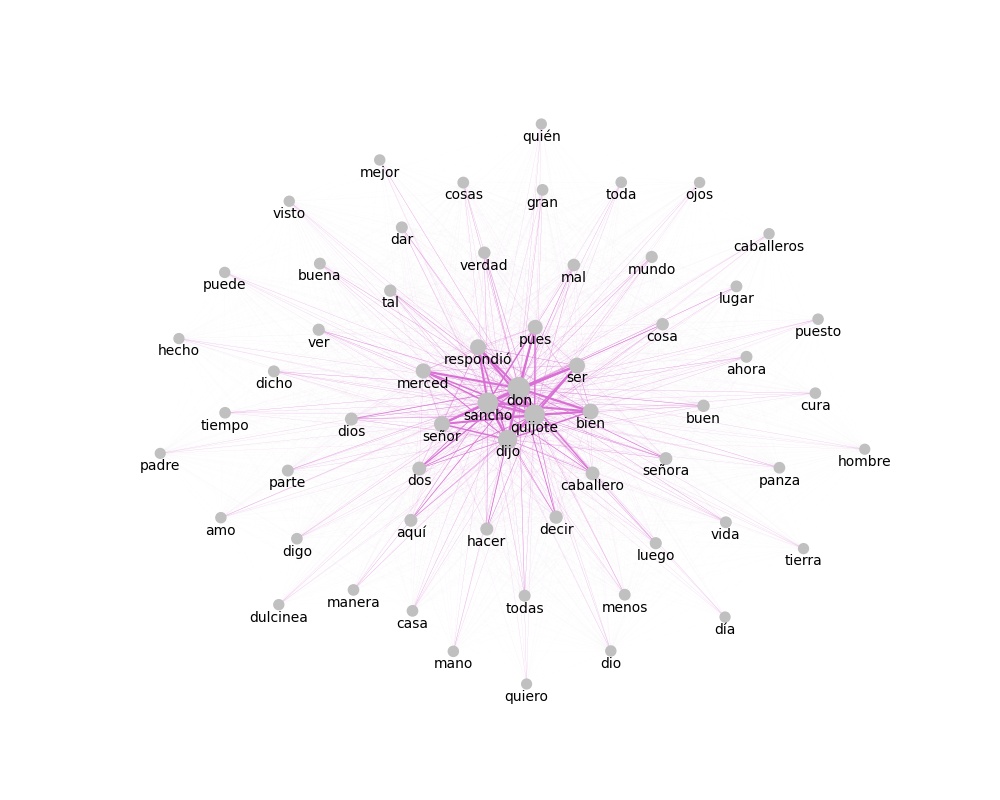
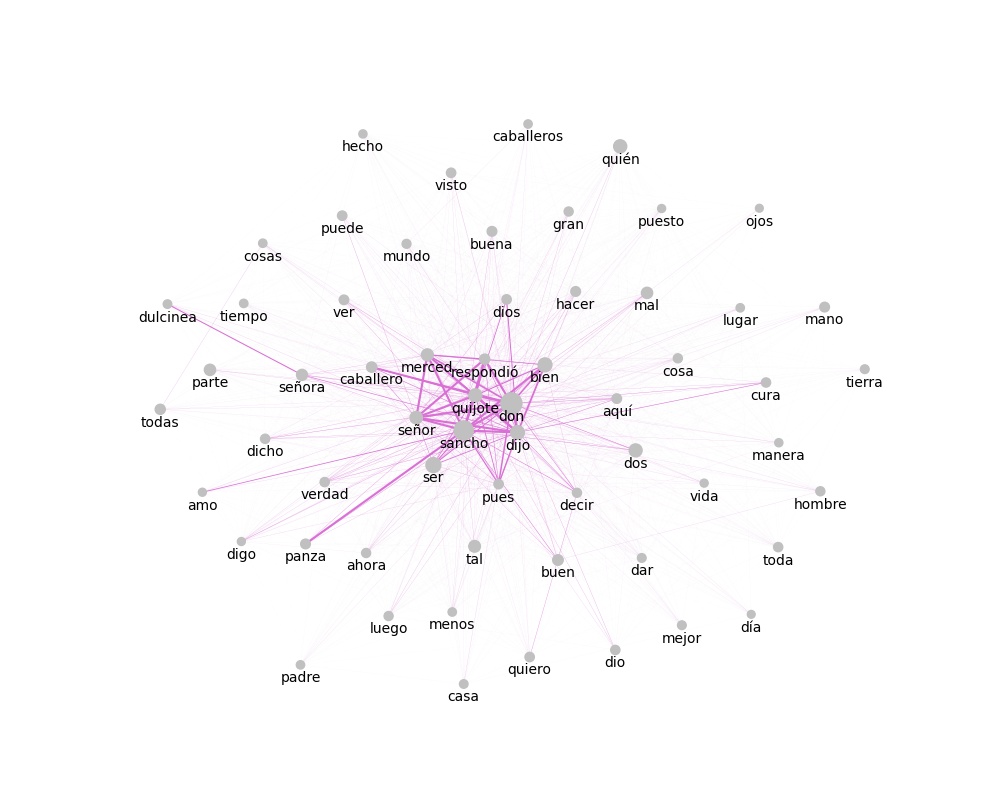
También se pueden calcular y graficar coocurrencias sobre un conjunto de documentos o textos independientes. Estos textos deben ser pasados como una lista.
>>> # Ejemplo con un grupo de textos
>>> textos = [
>>> 'el perro está en la casa',
>>> 'un perro y un gato están en el carro',
>>> 'el carro entro a la casa',
>>> 'el gato salió de la casa para entrar al carro',
>>> 'el carro casi atropella al perro']
>>> textos = [limpieza_texto(t, lista_palabras=lista_stopwords()) for t in textos]
>>> mat_doc = matriz_coocurrencias(textos)
>>> mat_ven = matriz_coocurrencias(textos, modo='ventana', ventana=2)
>>> graficar_coocurrencias(mat_doc, dim_figura=(4,4))
>>> graficar_coocurrencias(mat_ven, dim_figura=(4,4))